Découvrez Tamebi : Un Package Python Polyvalent pour Construire avec l'IA Open Source
Il existe un fossé entre vouloir utiliser l'IA open source et l'utiliser réellement. Pas un fossé de connaissances. Pas un manque d'intérêt. Un fossé d'infrastructure. Les développeurs passent des heures à déterminer quels modèles correspondent à leur matériel, comment connecter l'inférence, comment construire des agents qui fonctionnent vraiment en production. Les outils pour l'IA open source ont été fragmentés, spécifiques au matériel, et difficiles à appréhender. Ce package est notre réponse à tout ça.
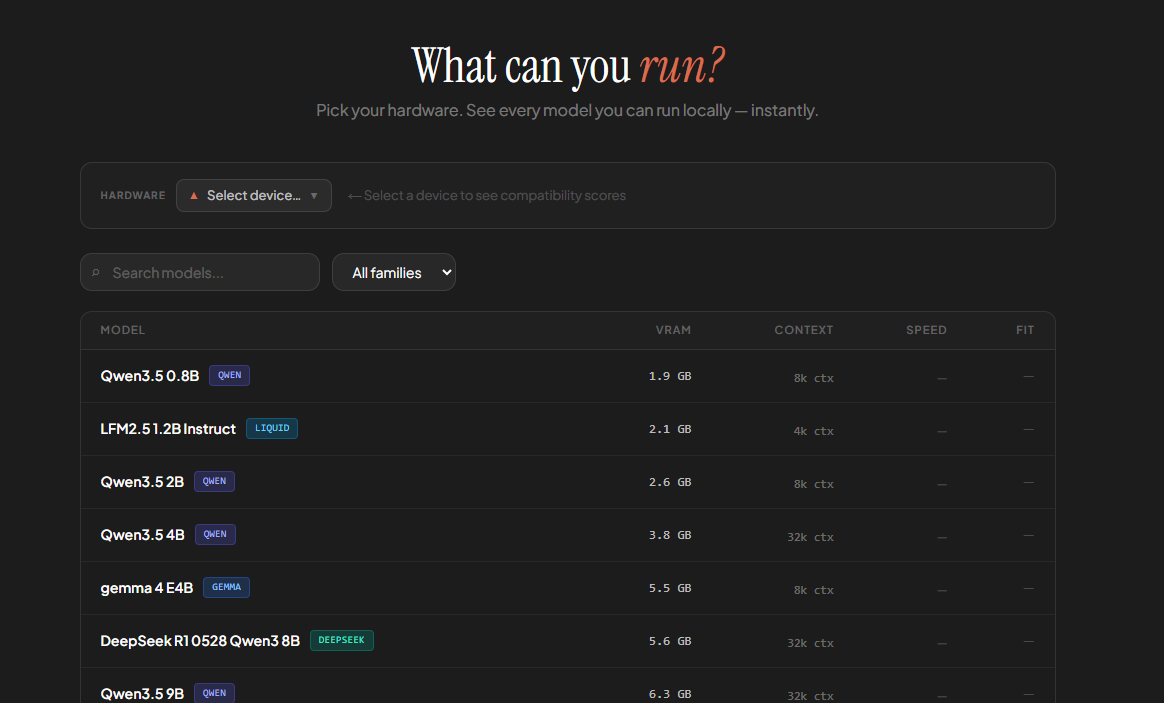



C'est quoi Tamebi ?
Tamebi est un package/CLI Python polyvalent pour travailler avec des modèles d'IA open source. De la compréhension de ce que vous pouvez exécuter, à l'exécution elle-même, jusqu'à la construction par-dessus. Pensez-y comme vous pensez au package openai, mais pour l'écosystème open source : une bibliothèque unique et cohérente qui évolue avec vous, de votre première expérience jusqu'au déploiement en production.
Nous la construisons fonctionnalité par fonctionnalité, en public, et nous ne faisons que commencer.
La première fonctionnalité : savoir ce que vous pouvez exécuter
La partie la plus difficile pour démarrer avec l'IA locale n'est pas la motivation. C'est l'incertitude.
Mon ordinateur peut-il faire tourner un modèle 7B ? Et 14B ? Dois-je utiliser FP16 ou INT4 ? Qu'arrive-t-il à la mémoire si j'étends le contexte à 32K ? Puis-je servir plusieurs utilisateurs simultanément ?
Ces questions ont de vraies réponses, mais les trouver aujourd'hui implique de croiser des benchmarks, lire des issues GitHub et faire des calculs mentaux. C'est une friction qui arrête les gens avant même qu'ils commencent.
Alors nous avons créé tamebi check : une seule commande qui scanne automatiquement votre matériel et vous dit exactement quels modèles s'y adaptent, à quelle précision, avec quelles performances attendues.
pip install tamebi
# ou, plus rapide :
uv pip install tamebi
tamebi checkEn quelques secondes, vous obtenez :
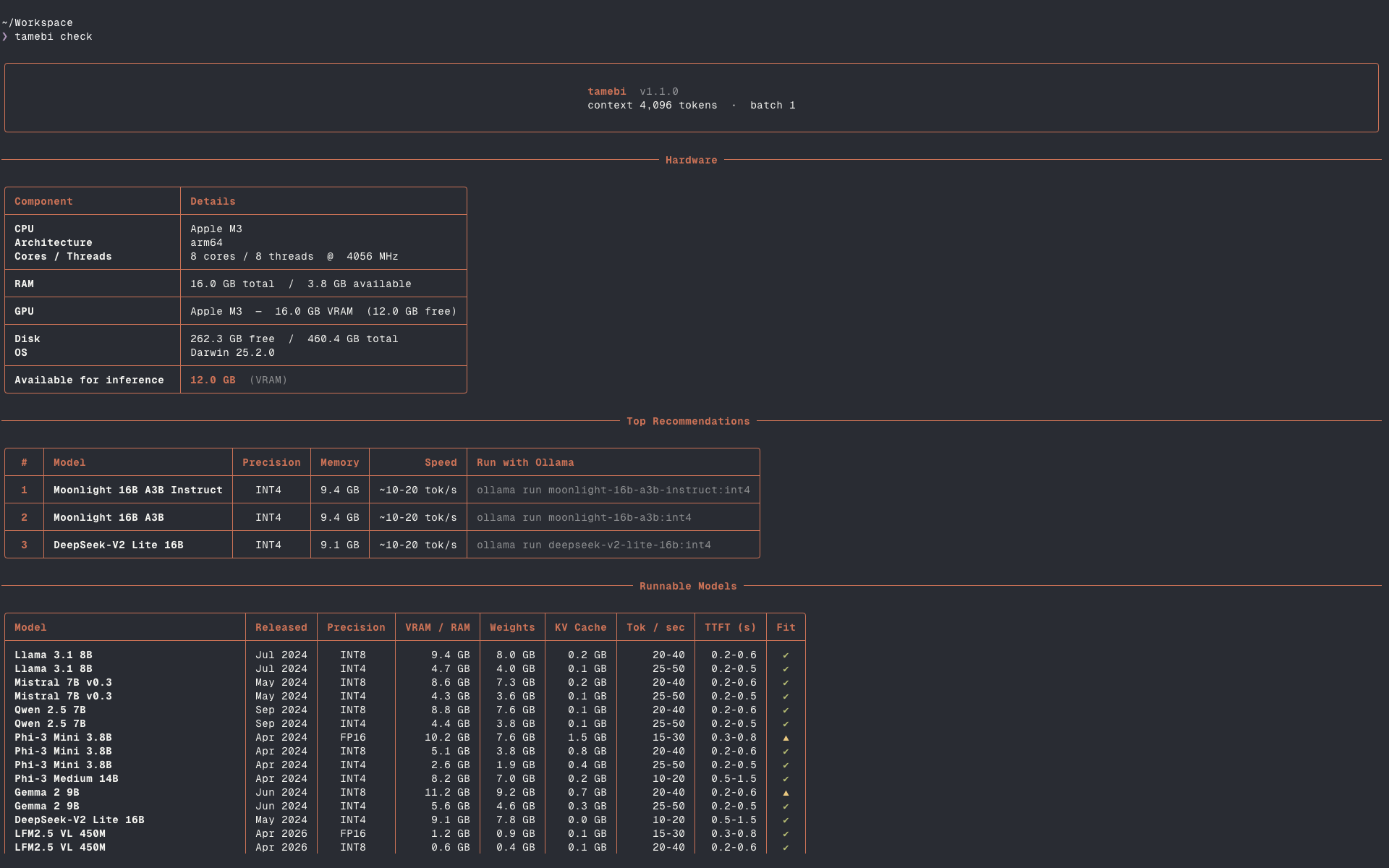
Un profil matériel complet (CPU, RAM, GPU/VRAM, OS)
Une matrice de compatibilité classée en INT4, INT8 et FP16
Une estimation des tokens/sec et du temps jusqu'au premier token
Des commandes Ollama prêtes à copier pour chaque modèle compatible
Des estimations de service multi-utilisateurs avec
--batch-sizeUne sortie JSON pour l'automatisation et les scripts
Fonctionne automatiquement sur NVIDIA, AMD, Apple Silicon et les systèmes CPU uniquement, sans configuration, sans options supplémentaires, sans approximations.
C'est la v1. Elle fait déjà économiser des heures d'essais et d'erreurs. Mais c'est la fondation, pas le plafond.
Ce qui arrive
La détection du matériel n'est que le point d'entrée. Nous construisons Tamebi pour en faire quelque chose de bien plus vaste :
Inférence de modèles : exécuter des modèles open source directement via le package, avec une API propre et cohérente
Primitives pour agents : outils, mémoire et orchestration pour construire des agents IA sur des modèles locaux ou distants
Abstraction de fournisseurs : passer de l'inférence locale aux API cloud et aux configurations hybrides sans réécrire votre code
Évaluation et benchmarking : comprendre la qualité d'un modèle, pas seulement sa compatibilité matérielle
Outils de déploiement : passer du prototype local au déploiement edge ou serveur avec moins de friction
L'objectif est que Tamebi soit le package vers lequel vous vous tournez dès que vous construisez avec l'IA open source, que vous soyez un étudiant qui fait tourner son premier modèle, un développeur qui lance un produit, ou une équipe qui planifie son infrastructure.
Pour qui
Les développeurs qui construisent des applications propulsées par l'IA
Les chercheurs qui évaluent des modèles avant de s'engager
Les étudiants qui explorent l'inférence locale pour la première fois
Les équipes de startups qui dimensionnent leur stack avant de passer à l'échelle
Les ingénieurs plateforme qui planifient des déploiements edge
Tous ceux qui veulent travailler avec l'IA open source sans se battre contre les outils
La documentation est disponible sur lab.tamebi.ai/docs. Le catalogue de modèles couvre les modèles de Meta, Mistral, Google, Qwen, DeepSeek, Kimi, Liquid, AllenAI et bien d'autres, et se met à jour chaque semaine.
Ce n'est que le début. Nous construisons en public, et nous serions ravis de savoir ce que vous voulez que Tamebi fasse ensuite.